实用脚本片段
这里汇总了一些小脚本片段,帮助你快速上手 Tabular Editor 的 高级脚本功能。 其中很多脚本都适合保存为 自定义操作,这样你就可以通过上下文菜单轻松复用它们。'
另外,也别忘了看看我们的脚本库 @csharp-script-library,里面有更多贴近实际场景的示例,展示了你可以如何利用 Tabular Editor 的脚本功能。
Tip
如需查阅关于 C# Script 和 Dynamic LINQ 的结构化、按模式逐一讲解的参考资料,请参阅脚本模式的操作指南系列。 完整的 TOM 包装器 API 请参阅 @api-index。
从列创建度量值
// 为当前选中的每一列创建一个 SUM 度量值,并隐藏该列。
foreach(var c in Selected.Columns)
{
var newMeasure = c.Table.AddMeasure(
"Sum of " + c.Name, // 名称
"SUM(" + c.DaxObjectFullName + ")", // DAX 表达式
c.DisplayFolder // 显示文件夹
);
// 为新度量值设置格式字符串:
newMeasure.FormatString = "0.00";
// 添加一些说明:
newMeasure.Description = "这个度量值是列 " + c.DaxObjectFullName + " 的总和";
// 隐藏原始列:
c.IsHidden = true;
}
这个片段使用 <Table>.AddMeasure(<name>, <expression>, <displayFolder>) 函数,在表中创建一个新的度量值。 我们使用 DaxObjectFullName 属性来获取列的完全限定名称,以便在 DAX 表达式中使用:'TableName'[ColumnName]。
生成时间智能度量值
首先,为每项时间智能聚合创建自定义操作。 例如:
// 为每个选中的度量值创建一个 TOTALYTD 度量值。
foreach(var m in Selected.Measures) {
m.Table.AddMeasure(
m.Name + " YTD", // 名称
"TOTALYTD(" + m.DaxObjectName + ", 'Date'[Date])", // DAX 表达式
m.DisplayFolder // 显示文件夹
);
}
这里我们使用 DaxObjectName 属性来生成用于 DAX 表达式的不带限定符的引用,因为这是一个度量值:[MeasureName]。 将其保存为一个适用于度量值的时间智能自定义操作,命名为 "Time Intelligence\Create YTD measure"。 为 MTD、LY 以及其他你需要的类型创建类似的操作。 然后,新建一个操作,并填入下面的脚本:
// 调用所有时间智能自定义操作:
CustomAction(@"Time Intelligence\Create YTD measure");
CustomAction(@"Time Intelligence\Create MTD measure");
CustomAction(@"Time Intelligence\Create LY measure");
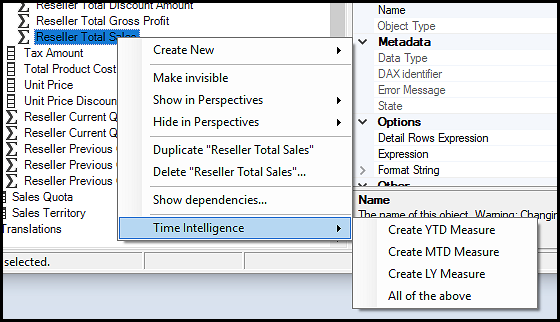
这展示了如何在一个操作中调用另一个操作来执行一个(或多个)自定义操作(注意避免循环引用,否则会导致 Tabular Editor 崩溃)。 将其另存为新的自定义操作“Time Intelligence\All of the above”,即可通过一次单击轻松生成所有时间智能度量值:
当然,你也可以将所有时间智能计算放入一个脚本中,如下所示:
var dateColumn = "'Date'[Date]";
// 为每个所选度量值创建时间智能度量值:
foreach(var m in Selected.Measures) {
// 年初至今:
m.Table.AddMeasure(
m.Name + " YTD", // 名称
"TOTALYTD(" + m.DaxObjectName + ", " + dateColumn + ")", // DAX 表达式
m.DisplayFolder // 显示文件夹
);
// 上年同期:
m.Table.AddMeasure(
m.Name + " PY", // 名称
"CALCULATE(" + m.DaxObjectName + ", SAMEPERIODLASTYEAR(" + dateColumn + "))", // DAX 表达式
m.DisplayFolder // 显示文件夹
);
// 同比:
m.Table.AddMeasure(
m.Name + " YoY", // 名称
m.DaxObjectName + " - [" + m.Name + " PY]", // DAX 表达式
m.DisplayFolder // 显示文件夹
);
// 同比%:
m.Table.AddMeasure(
m.Name + " YoY%", // 名称
"DIVIDE([" + m.Name + " YoY], [" + m.Name + " PY])", // DAX 表达式
m.DisplayFolder // 显示文件夹
).FormatString = "0.0 %"; // 将格式字符串设置为百分比
// 季度至今:
m.Table.AddMeasure(
m.Name + " QTD", // 名称
"TOTALQTD(" + m.DaxObjectName + ", " + dateColumn + ")", // DAX 表达式
m.DisplayFolder // 显示文件夹
);
// 本月至今:
m.Table.AddMeasure(
m.Name + " MTD", // 名称
"TOTALMTD(" + m.DaxObjectName + ", " + dateColumn + ")", // DAX 表达式
m.DisplayFolder // 显示文件夹
);
}
包含附加属性
如果你想为新建的度量值设置其他属性,可以将上述脚本修改如下:
// 为每个所选度量值创建一个 TOTALYTD 度量值。
foreach(var m in Selected.Measures) {
var newMeasure = m.Table.AddMeasure(
m.Name + " YTD", // 名称
"TOTALYTD(" + m.DaxObjectName + ", 'Date'[Date])", // DAX 表达式
m.DisplayFolder // 显示文件夹
);
newMeasure.FormatString = m.FormatString; // 从原度量值复制格式字符串
foreach(var c in Model.Cultures) {
newMeasure.TranslatedNames[c] = m.TranslatedNames[c] + " YTD"; // 为每种区域设置复制已翻译的名称
newMeasure.TranslatedDisplayFolders[c] = m.TranslatedDisplayFolders[c]; // 复制已翻译的显示文件夹
}
}
设置默认翻译
有时,为所有(可见)对象应用默认翻译会很有用。 在这种情况下,默认翻译其实就是对象的原始名称/描述/显示文件夹。 这样做的一个好处是:以 JSON 格式导出翻译时,会包含所有翻译对象,即可用于 SSAS Tabular Translator。
以下脚本会遍历模型中的所有区域设置;对于每个可见对象,若尚无翻译,则会为其赋予默认值:
// 将默认翻译应用到模型中所有区域设置下的所有(可见)可翻译对象:
foreach(var culture in Model.Cultures)
{
ApplyDefaultTranslation(Model, culture);
foreach(var perspective in Model.Perspectives)
ApplyDefaultTranslation(perspective, culture);
foreach(var table in Model.Tables.Where(t => t.IsVisible))
ApplyDefaultTranslation(table, culture);
foreach(var measure in Model.AllMeasures.Where(m => m.IsVisible))
ApplyDefaultTranslation(measure, culture);
foreach(var column in Model.AllColumns.Where(c => c.IsVisible))
ApplyDefaultTranslation(column, culture);
foreach(var hierarchy in Model.AllHierarchies.Where(h => h.IsVisible))
ApplyDefaultTranslation(hierarchy, culture);
foreach(var level in Model.AllLevels.Where(l => l.Hierarchy.IsVisible))
ApplyDefaultTranslation(level, culture);
}
void ApplyDefaultTranslation(ITranslatableObject obj, Culture culture)
{
// 仅当还没有翻译时,才应用默认翻译:
if(string.IsNullOrEmpty(obj.TranslatedNames[culture]))
{
// 默认名称翻译:
obj.TranslatedNames[culture] = obj.Name;
// 默认描述翻译:
var dObj = obj as IDescriptionObject;
if(dObj != null && string.IsNullOrEmpty(obj.TranslatedDescriptions[culture])
&& !string.IsNullOrEmpty(dObj.Description))
{
obj.TranslatedDescriptions[culture] = dObj.Description;
}
// 默认显示文件夹翻译:
var fObj = obj as IFolderObject;
if(fObj != null && string.IsNullOrEmpty(fObj.TranslatedDisplayFolders[culture])
&& !string.IsNullOrEmpty(fObj.DisplayFolder))
{
fObj.TranslatedDisplayFolders[culture] = fObj.DisplayFolder;
}
}
}
处理透视
度量值、列、层次结构和表都公开了 InPerspective 属性。该属性会为模型中的每个透视保存一个 True/False 值,用于指示给定对象是否属于该透视。 比如:
foreach(var measure in Selected.Measures)
{
measure.InPerspective["Inventory"] = true;
measure.InPerspective["Reseller Operation"] = false;
}
上述脚本可确保所有选中的度量值在 "Inventory" 透视中可见,并在 "Reseller Operation" 透视中隐藏。
除了获取/设置单个透视中的成员关系外,InPerspective 属性还支持以下方法:
<<object>>.InPerspective.None()- 将对象从所有透视中移除。<<object>>.InPerspective.All()- 将对象加入所有透视。<<object>>.CopyFrom(string[] perspectives)- 将对象加入所有指定的透视中(包含透视名称的字符串数组)。<<object>>.CopyFrom(perspectiveIndexer perspectives)- 从另一个InPerspective属性复制透视包含关系。
后一种方法可用于将透视成员关系从一个对象复制到另一个对象。 例如,假设你有一个基础度量值 [Reseller Total Sales],并希望确保当前选中的所有度量值在与该基础度量值相同的透视中都可见。 下面的脚本即可实现这一点:
var baseMeasure = Model.Tables["Reseller Sales"].Measures["Reseller Total Sales"];
foreach(var measure in Selected.Measures)
{
/* 如果你希望在 'baseMeasure' 被隐藏的那些透视中,'measure' 也一并隐藏,
请取消注释下面这一行: */
// measure.InPerspective.None();
measure.InPerspective.CopyFrom(baseMeasure.InPerspective);
}
这种技巧也可用于通过代码生成新对象。 例如,如果我们希望确保自动生成的时间智能度量值只在与其基础度量值相同的透视中可见,可以在上一节的脚本基础上扩展如下:
// 为每个选中的度量值创建一个 TOTALYTD 度量值。
foreach(var m in Selected.Measures) {
var newMeasure = m.Table.AddMeasure(
m.Name + " YTD", // 名称
"TOTALYTD(" + m.DaxObjectName + ", 'Date'[Date])", // DAX 表达式
m.DisplayFolder // 显示文件夹
);
newMeasure.InPerspective.CopyFrom(m.InPerspective); // 应用基础度量值的透视设置
}
生成分区
如果你需要对某个表进行自定义分区,C# Script 可以帮你快速生成大量分区。 基本思路是:为表添加一个注释,其中包含一个 SQL 或 M 查询,作为每个分区的模板。 然后脚本会根据需要替换筛选参数。 例如,使用 SQL 分区时,你可以添加一个名为 PartitionTemplateSQL 的注释,并将其值设置为 SELECT * FROM fact_ResellerSales WHERE CalendarID BETWEEN {0} AND {1}。 在生成最终分区时,我们的脚本会替换 {0} 和 {1} 占位符。 在此例中,CalendarID 是整数;但一般来说,你需要确保最终得到的字符串是有效的 SQL(或 M)查询。

这里的示例会按月生成分区。 选择一个带有 PartitionTemplateSQL 分区注释的表,然后运行该脚本。
var firstPartition = new DateTime(2018,1,1); // 第一个分区日期
var lastPartition = new DateTime(2020,12,1); // 最后一个分区日期
var templateSql = Selected.Table.GetAnnotation("PartitionTemplateSQL");
if(string.IsNullOrEmpty(templateSql)) throw new Exception("No partition template!");
var currentPartition = firstPartition;
while(currentPartition <= lastPartition)
{
// 根据 currentPartition 日期计算 CalendarID 的起止值(整数):
var calendarIdFrom = currentPartition.ToString("yyyyMMdd");
var calendarIdTo = currentPartition.AddMonths(1).AddDays(-1).ToString("yyyyMMdd");
// 为分区生成唯一名称——由于按月分区,这里直接使用 yyyyMM:
var partitionName = Selected.Table.Name + "_" + currentPartition.ToString("yyyyMM");
// 将分区模板 SQL 中的占位符替换为实际值:
var partitionQuery = string.Format(templateSql, calendarIdFrom, calendarIdTo);
// 创建分区(如果使用的是 M 查询模板而非 SQL,请改用 .AddMPartition):
Selected.Table.AddPartition(partitionName, partitionQuery);
// 递增到下一个月(如需更多/更少分区,可改用 .AddDays、.AddYears 等):
currentPartition = currentPartition.AddMonths(1);
}
将对象属性导出到文件
在某些工作流中,使用 Excel 批量编辑多个对象的属性可能会很有帮助。 使用以下代码片段可以将一组标准属性导出到 .TSV 文件,之后还可以再将其导入(见下文)。
// 导出当前选中对象的属性:
var tsv = ExportProperties(Selected);
SaveFile("Exported Properties 1.tsv", tsv);
在 Excel 中打开后,生成的 .TSV 文件如下所示:
 第一列(Object)中的内容是对该对象的引用。 如果更改了该列内容,后续导入这些属性时可能无法正常进行。 如果你想修改对象名称,只需更改第二列(Name)中的值。
第一列(Object)中的内容是对该对象的引用。 如果更改了该列内容,后续导入这些属性时可能无法正常进行。 如果你想修改对象名称,只需更改第二列(Name)中的值。
默认情况下,文件会保存到 TabularEditor.exe 所在的文件夹中。 默认情况下,仅导出以下属性(如适用,具体取决于所导出对象的类型):
- 名称
- 描述
- 源列
- 表达式
- 格式字符串
- 数据类型
要导出不同的属性,请提供以逗号分隔的属性名称列表,作为 ExportProperties 的第 2 个参数:
// 导出当前选定表中所有度量值的名称和明细行表达式:
var tsv = ExportProperties(Selected.Table.Measures, "Name,DetailRowsExpression");
SaveFile("Exported Properties 2.tsv", tsv);
可用的属性名称可在 TOM API 文档 中找到。 这些名称大多与 Tabular Editor 属性网格中显示的名称一致,只是采用 CamelCase 并去掉了空格(少数情况例外,例如,“Hidden” 属性在 TOM API 中称为 IsHidden)。
要导入属性,请使用以下代码片段:
// 导入并应用指定文件中的属性:
var tsv = ReadFile("Exported Properties 1.tsv");
ImportProperties(tsv);
导出带索引的属性
从 Tabular Editor 2.11.0 起,ExportProperties 和 ImportProperties 方法支持带索引的属性。 带索引的属性是指除了属性名称外,还需要一个键值的属性。 一个示例是 myMeasure.TranslatedNames。 该属性表示应用于 myMeasure 的所有名称翻译字符串的集合。 在 C# 中,你可以使用索引运算符访问特定区域设置的翻译后的标题:myMeasure.TranslatedNames["da-DK"]。
简而言之,你现在可以导出 Tabular 模型中对象的所有翻译、透视信息、注释、扩展属性,以及行级和对象级安全性信息。
例如,以下脚本会生成一个 TSV 文件,其中包含模型中所有度量值以及每个度量值在哪些透视中可见的信息:
var tsv = ExportProperties(Model.AllMeasures, "Name,InPerspective");
SaveFile(@"c:\Project\MeasurePerspectives.tsv", tsv);
在 Excel 中打开后,TSV 文件如下所示:

正如上面所示,你可以在 Excel 中进行修改,保存后,再使用 ImportProperties 将更新后的值加载回 Tabular Editor。
如果你只想列出某一个或少数几个特定的透视,可以在调用 ExportProperties 时在第 2 个参数中指定:
var tsv = ExportProperties(Model.AllMeasures, "Name,InPerspective[Inventory]");
SaveFile(@"c:\Project\MeasurePerspectiveInventory.tsv", tsv);
同理,翻译、注释等也是如此。 例如,如果你想查看应用于表、列、层次结构、级别和度量值的所有丹麦语翻译:
// 构造对象列表:
var objects = new List<TabularNamedObject>();
objects.AddRange(Model.Tables);
objects.AddRange(Model.AllColumns);
objects.AddRange(Model.AllHierarchies);
objects.AddRange(Model.AllLevels);
objects.AddRange(Model.AllMeasures);
var tsv = ExportProperties(objects, "Name,TranslatedNames[da-DK],TranslatedDescriptions[da-DK],TranslatedDisplayFolders[da-DK]");
SaveFile(@"c:\Project\ObjectTranslations.tsv", tsv);
生成文档
如果你想为模型的全部或部分内容生成文档,也可以使用上面展示的 ExportProperties 方法。 下面的代码片段会从 Tabular 模型中所有可见的度量值或列中提取一组属性,并将其保存为 TSV 文件:
// 构造所有可见列和度量值的列表:
var objects = Model.AllMeasures.Where(m => !m.IsHidden && !m.Table.IsHidden).Cast<ITabularNamedObject>()
.Concat(Model.AllColumns.Where(c => !c.IsHidden && !c.Table.IsHidden));
// 以 TSV 格式获取其属性(制表符分隔):
var tsv = ExportProperties(objects,"Name,ObjectType,Parent,Description,FormatString,DataType,Expression");
// (可选)输出到屏幕上(然后可以复制粘贴到 Excel 中):
// tsv.Output();
// ……或者将 TSV 保存到文件:
SaveFile("documentation.tsv", tsv);
从文件生成度量值
如果你想批量编辑模型中现有对象的属性,上述导出/导入属性的方法会很有用。 如果你想导入一个尚不存在的度量值列表,该怎么办?
假设你有一个 TSV(制表符分隔值)文件,其中包含要导入到现有 Tabular 模型中的度量值名称、说明和 DAX 表达式。 你可以使用下面的脚本读取该文件,将其拆分为行和列,并生成这些度量值。 该脚本还会为每个度量值分配一个特殊注释,这样它就能删除之前使用同一脚本创建的度量值。
var targetTable = Model.Tables["Program"]; // 用于存放这些度量值的表的名称
var measureMetadata = ReadFile(@"c:\Test\MyMeasures.tsv"); // c:\Test\MyMeasures.tsv 是一个带标题行的制表符分隔文件,包含 3 列:Name、Description、Expression
// 删除目标表中所有带有值为 "1" 的 "AUTOGEN" 注释的度量值:
foreach(var m in targetTable.Measures.Where(m => m.GetAnnotation("AUTOGEN") == "1").ToList())
{
m.Delete();
}
// 按 CR 和 LF 字符将文件拆分为多行:
var tsvRows = measureMetadata.Split(new[] {'\r','\n'},StringSplitOptions.RemoveEmptyEntries);
// 遍历所有行,但跳过第一行:
foreach(var row in tsvRows.Skip(1))
{
var tsvColumns = row.Split('\t'); // 假设文件使用制表符作为列分隔符
var name = tsvColumns[0]; // 第 1 列是度量值名称
var description = tsvColumns[1]; // 第 2 列是度量值说明
var expression = tsvColumns[2]; // 第 3 列是度量值表达式
// 这里假设模型中还没有同名度量值(如果存在,新度量值会自动加上数字后缀):
var measure = targetTable.AddMeasure(name);
measure.Description = description;
measure.Expression = expression;
measure.SetAnnotation("AUTOGEN", "1"); // 在该度量值上设置一个特殊注释,这样下次执行脚本时就能找到它并将其删除。
}
如果你需要将此流程自动化,可以把上面的脚本保存到文件中,然后按如下方式使用 Tabular Editor CLI:
start /wait TabularEditor.exe "<path to bim file>" -S "<path to script file>" -B "<path to modified bim file>"
比如:
start /wait TabularEditor.exe "c:\Projects\AdventureWorks\Model.bim" -S "c:\Projects\AutogenMeasures.cs" -B "c:\Projects\AdventureWorks\Build\Model.bim"
……或者,如果你想针对已部署的数据库运行该脚本:
start /wait TabularEditor.exe "localhost" "AdventureWorks" -S "c:\Projects\AutogenMeasures.cs" -D "localhost" "AdventureWorks" -O
根据分区源元数据创建数据列
Note
下文所述的 RefreshDataColumns() 方法仅在 Tabular Editor 2 中可用。 在 Tabular Editor 3 中,请改用 Import Table... 功能。
如果某个表使用基于 OLE DB Provider数据源的查询分区,我们可以通过执行以下代码片段来自动刷新该表的列元数据:
Model.Tables["Reseller Sales"].RefreshDataColumns();
这在向模型添加新表时很有用,可避免需要在表上逐个手动创建数据列。 上述代码片段假定可在本地访问该分区源,并使用“Reseller Sales”表分区源的现有连接字符串。 上述代码片段会从分区查询中提取架构信息,并为源查询中的每一列在表中添加一个数据列。
如果需要为此操作提供另一条连接字符串,也可以在该代码片段中进行设置:
var source = Model.DataSources["DWH"] as ProviderDataSource;
var oldConnectionString = source.ConnectionString;
source.ConnectionString = "..."; // 输入要用于元数据刷新的连接字符串
Model.Tables["Reseller Sales"].RefreshDataColumns();
source.ConnectionString = oldConnectionString;
这里假定“Reseller Sales”表的分区使用名为“DWH”的 Provider数据源。
格式化 DAX 表达式
更多信息请参见 FormatDax。
// 适用于 Tabular Editor 2.13.0 或更高版本:
Selected.Measures.FormatDax();
另一种语法:
// 适用于 Tabular Editor 2.13.0 或更高版本:
foreach(var m in Selected.Measures)
m.FormatDax();
生成表的源列列表
下面的脚本会为当前选定的表输出一份格式良好的源列清单。 如果你想将使用 SELECT * 的分区查询替换为显式列清单,这会很有用。
string.Join(",\r\n",
Selected.Table.DataColumns
.OrderBy(c => c.SourceColumn)
.Select(c => "[" + c.SourceColumn + "]")
).Output();
自动生成关系
如果你的团队一直采用一套固定的命名约定,你很快就会发现脚本的威力会更大。
在一个或多个事实表上执行以下脚本后,脚本会根据列名自动创建与所有相关维度表的关系。 脚本会查找事实表中名称符合 xxxyyyKey 模式的列,其中 xxx 是用于角色扮演维度的可选限定符,yyy 是维度表名称。 在维度表中必须有一列名为 yyyKey,且其数据类型必须与事实表上的对应列相同。 例如,名为“ProductKey”的列会与 Product 表中的“ProductKey”列建立关系。 你也可以指定其他列名后缀来替换“Key”。
如果事实表与维度表之间已经存在关系,脚本会将新关系创建为非活动状态。
var keySuffix = "Key";
// 遍历当前选中的所有表(假定为事实表):
foreach(var fact in Selected.Tables)
{
// 遍历当前表中的所有 SK 列:
foreach(var factColumn in fact.Columns.Where(c => c.Name.EndsWith(keySuffix)))
{
// 查找与当前 SK 列对应的维度表:
var dim = Model.Tables.FirstOrDefault(t => factColumn.Name.EndsWith(t.Name + keySuffix));
if(dim != null)
{
// 查找维度表上的键列:
var dimColumn = dim.Columns.FirstOrDefault(c => factColumn.Name.EndsWith(c.Name));
if(dimColumn != null)
{
// 检查这两列之间是否已存在关系:
if(!Model.Relationships.Any(r => r.FromColumn == factColumn && r.ToColumn == dimColumn))
{
// 如果这两个表之间已存在关系,新关系将创建为非活动状态:
var makeInactive = Model.Relationships.Any(r => r.FromTable == fact && r.ToTable == dim);
// 添加新关系:
var rel = Model.AddRelationship();
rel.FromColumn = factColumn;
rel.ToColumn = dimColumn;
factColumn.IsHidden = true;
if(makeInactive) rel.IsActive = false;
}
}
}
}
}
创建 DumpFilters 度量值
受这篇文章启发,下面的脚本会在当前选中的表上创建一个名为 [DumpFilters] 的度量值:
var dax = "VAR MaxFilters = 3 RETURN ";
var dumpFilterDax = @"IF (
ISFILTERED ( {0} ),
VAR ___f = FILTERS ( {0} )
VAR ___r = COUNTROWS ( ___f )
VAR ___t = TOPN ( MaxFilters, ___f, {0} )
VAR ___d = CONCATENATEX ( ___t, {0}, "", "" )
VAR ___x = ""{0} = "" & ___d
& IF(___r > MaxFilters, "", ... ["" & ___r & "" 个项目已选择]"") & "" ""
RETURN ___x & UNICHAR(13) & UNICHAR(10)
)";
// 遍历模型中的所有列,以构建完整的 DAX 表达式:
bool first = true;
foreach(var column in Model.AllColumns)
{
if(!first) dax += " & ";
dax += string.Format(dumpFilterDax, column.DaxObjectFullName);
if(first) first = false;
}
// 将度量值添加到当前选中的表:
Selected.Table.AddMeasure("DumpFilters", dax);
将 CamelCase 转换为 Proper Case
在关系数据库中,列和表常用的一种命名方式是 CamelCase。 也就是说,名称中不含任何空格,且每个单词都以大写字母开头。 在 Tabular 模型中,未隐藏的表和列会对业务用户可见,因此通常更适合使用更“易读”的命名方式。 以下脚本会将 CamelCased 名称转换为 Proper Case。 连续的大写字母会原样保留(作为首字母缩写)。 例如,该脚本会将以下内容转换为:
CustomerWorkZipcode转换为Customer Work ZipcodeCustomerAccountID转换为Customer Account IDNSASecurityID转换为NSA Security ID
强烈建议将该脚本保存为适用于所有对象类型的自定义操作(关系、KPI、表格权限和翻译除外,因为这些对象没有可编辑的“Name”属性):
foreach(var obj in Selected.OfType<ITabularNamedObject>()) {
var oldName = obj.Name;
var newName = new System.Text.StringBuilder();
for(int i = 0; i < oldName.Length; i++) {
// 首字母应始终大写:
if(i == 0) newName.Append(Char.ToUpper(oldName[i]));
// 两个大写字母后紧跟一个小写字母时,应在第一个字母后插入空格:
else if(i + 2 < oldName.Length && char.IsLower(oldName[i + 2]) && char.IsUpper(oldName[i + 1]) && char.IsUpper(oldName[i]))
{
newName.Append(oldName[i]);
newName.Append(" ");
}
// 其他所有“小写字母 + 大写字母”的情况,也应在第一个字母后插入空格:
else if(i + 1 < oldName.Length && char.IsLower(oldName[i]) && char.IsUpper(oldName[i+1]))
{
newName.Append(oldName[i]);
newName.Append(" ");
}
else
{
newName.Append(oldName[i]);
}
}
obj.Name = newName.ToString();
}
导出表与度量值的依赖关系
假设你有一个大型且复杂的模型,并希望了解哪些度量值可能会受到底层数据变更的影响。
下面的脚本会遍历模型中的所有度量值,并针对每个度量值输出其依赖的表列表——包括直接依赖和间接依赖。 该列表会输出为制表符分隔文件。
string tsv = "度量值\tDependsOnTable"; // TSV 文件表头行
// 遍历所有度量值:
foreach(var m in Model.AllMeasures) {
// 获取此度量值引用的 ALL 对象列表(既包括直接引用,也包括通过其他度量值间接引用):
var allReferences = m.DependsOn.Deep();
// 将上面的引用列表筛选为仅包含表的引用。对于列引用,获取每列所属的表。
// 最后,仅保留不重复的表:
var allTableReferences = allReferences.OfType<Table>()
.Concat(allReferences.OfType<Column>().Select(c => c.Table)).Distinct();
// 输出 TSV 行——每个表引用一行:
foreach(var t in allTableReferences)
tsv += string.Format("\r\n{0}\t{1}", m.Name, t.Name);
}
tsv.Output();
// SaveFile("c:\\MyProjects\\SSAS\\MeasureTableDependencies.tsv", tsv); // 取消注释这一行即可将输出保存到文件
设置聚合(仅适用于 Power BI Dataset)
从 Tabular Editor 2.11.3 起,你可以在列上设置 AlternateOf 属性,从而在模型中定义聚合表。 此功能可通过 Power BI 服务的 XMLA endpoint 在 Power BI Dataset(兼容级别 1460 或更高)中启用。
选择一组列并运行以下脚本,以初始化这些列的 AlternateOf 属性:
foreach(var col in Selected.Columns) col.AddAlternateOf();
接下来逐列处理,将它们映射到基础列,并相应设置汇总方式(Sum/Min/Max/GroupBy)。 或者,如果你想自动化此流程,并且聚合表中的列与基础表中的列名称完全相同,可以使用下面的脚本,它会为你自动映射这些列:
// 在树中选择两张表(Ctrl+单击)。默认聚合表是列数最少的那张。
// 这个脚本会为聚合表上的所有列设置 AlternateOf 属性。要让脚本生效,聚合表的列必须
// 与基础表的列同名。
var aggTable = Selected.Tables.OrderBy(t => t.Columns.Count).First();
var baseTable = Selected.Tables.OrderByDescending(t => t.Columns.Count).First();
foreach(var col in aggTable.Columns)
{
// 这个脚本会将汇总类型设置为 "Group By",除非该列使用的数据类型是 decimal/double:
var summarization = SummarizationType.GroupBy;
if(col.DataType == DataType.Double || col.DataType == DataType.Decimal)
summarization = SummarizationType.Sum;
col.AddAlternateOf(baseTable.Columns[col.Name], summarization);
}
运行脚本后,你应该会看到聚合表上的所有列都已设置了 AlternateOf 属性(见下方截图)。 请注意:要让聚合生效,基础表分区必须使用 DirectQuery。

查询 Analysis Services
自版本 2.12.1 起,Tabular Editor 提供了多种辅助方法,用于针对你的模型执行 DAX 查询并对 DAX 表达式求值。 这些方法仅在模型元数据直接从 Analysis Services 实例加载时才适用,例如使用 "File > Open > From DB..." 选项,或使用 Tabular Editor 与 Power BI 外部工具的集成功能时。
以下方法可用:
| 方法 | 描述 |
|---|---|
void ExecuteCommand(string tmslOrXmla, bool isXmla = false) |
这个方法会将指定的 TMSL 或 XMLA 脚本传递给已连接的 Analysis Services 实例。 当你想要刷新 AS 实例中某个表的数据时,这会很有用。 注意,如果你用这个方法更改模型元数据,本地模型元数据将与 AS 实例上的元数据不同步,并且下次尝试保存模型元数据时,你可能会收到版本冲突警告。 如果要发送 XMLA 脚本,请将 isXmla 参数设为 true。 |
IDataReader ExecuteReader(string dax) |
在已连接的 AS 数据库上执行指定的 DAX 查询,并返回得到的 AmoDataReader 对象。 DAX 查询由一个或多个 EVALUATE 语句组成。 注意,你不能同时打开多个数据读取器。 如果你忘记显式关闭或释放读取器,Tabular Editor 会自动关闭它们。 |
Dataset ExecuteDax(string dax) |
在已连接的 AS 数据库上执行指定的 DAX 查询,并返回一个 Dataset 对象,其中包含查询返回的数据。 DAX 查询由一个或多个 EVALUATE 语句组成。 返回的 Dataset 对象中,每个 EVALUATE 语句都会对应一个 DataTable。 不建议返回超大的数据表,因为这可能会导致内存不足或其他稳定性问题。 |
object EvaluateDax(string dax) |
对已连接的 AS 数据库执行指定的 DAX 表达式,并返回一个表示执行结果的对象。 如果 DAX 表达式是标量,则会返回相应类型的对象(string、long、decimal、double、DateTime)。 如果 DAX 表达式为表值,则会返回一个 DataTable。 |
这些方法属于 Model.Database 对象,但也可以不加任何前缀直接执行。
Darren Gosbell 在 此处 介绍了一个有趣的用例:如何使用 ExecuteDax 方法生成数据驱动的度量值。
另一种做法是创建一个可复用的脚本,用于刷新某个表。 例如,要执行重新计算,可使用下面的代码:
var type = "calculate";
var database = Model.Database.Name;
var table = Selected.Table.Name;
var tmsl = "{ \"refresh\": { \"type\": \"%type%\", \"objects\": [ { \"database\": \"%db%\", \"table\": \"%table%\" } ] } }"
.Replace("%type%", type)
.Replace("%db%", database)
.Replace("%table%", table);
ExecuteCommand(tmsl);
清除 Analysis Services 引擎的缓存
从 Tabular Editor 2.16.6 或 Tabular Editor 3.2.3 起,你可以使用以下语法向 Analysis Services 发送原始 XMLA 命令。 下面的示例展示了如何使用它来清除 AS 引擎缓存:
var clearCacheXmla = string.Format(@"<ClearCache xmlns=""http://schemas.microsoft.com/analysisservices/2003/engine"">
<Object>
<DatabaseID>{0}</DatabaseID>
</Object>
</ClearCache>", Model.Database.ID);
ExecuteCommand(clearCacheXmla, isXmla: true);
可视化查询结果
你也可以使用 Output 辅助方法,直接将 EvaluateDax 返回的 DAX 表达式结果可视化:
EvaluateDax("1 + 2").Output(); // 整数
EvaluateDax("\"Hello from AS\"").Output(); // 字符串
EvaluateDax("{ (1, 2, 3) }").Output(); // 表

...或者,如果你想返回当前选中度量值的值:
EvaluateDax(Selected.Measure.DaxObjectFullName).Output();

下面是一个更高级的示例,可让你一次选择并对多个度量值求值:
var dax = "ROW(" + string.Join(",", Selected.Measures.Select(m => "\"" + m.Name + "\", " + m.DaxObjectFullName).ToArray()) + ")";
EvaluateDax(dax).Output();

如果你已经非常熟练,可以使用 SUMMARIZECOLUMNS 或其他 DAX 函数,将选中的度量值按某一列切片并可视化:
var dax = "SUMMARIZECOLUMNS('Product'[Color], " + string.Join(",", Selected.Measures.Select(m => "\"" + m.Name + "\", " + m.DaxObjectFullName).ToArray()) + ")";
EvaluateDax(dax).Output();

别忘了点击脚本编辑器正上方的“+”图标,将这些脚本保存为自定义操作。 这样,你就能拥有一套易于复用的 DAX 查询集合,可直接在 Tabular Editor 的上下文菜单中执行并可视化:

数据导出
你可以使用下面的脚本通过 EVALUATE 执行一个 DAX 查询,并将结果流式写入文件(脚本使用制表符分隔格式):
using System.IO;
// 这个脚本会执行一个 DAX 查询,并以制表符分隔格式把结果写入文件:
var dax = "EVALUATE 'Customer'";
var file = @"c:\temp\file.csv";
var columnSeparator = "\t";
using(var daxReader = ExecuteReader(dax))
using(var fileWriter = new StreamWriter(file))
{
// 写入列标题:
fileWriter.WriteLine(string.Join(columnSeparator, Enumerable.Range(0, daxReader.FieldCount - 1).Select(f => daxReader.GetName(f))));
while(daxReader.Read())
{
var rowValues = new object[daxReader.FieldCount];
daxReader.GetValues(rowValues);
var row = string.Join(columnSeparator, rowValues.Select(v => v == null ? "" : v.ToString()));
fileWriter.WriteLine(row);
}
}
如果你想到了这些方法的其他有趣用法,欢迎在社区脚本 repository中分享。 谢谢!
替换 Power Query 的服务器和数据库名称
从基于 SQL Server 的数据源导入数据的 Power BI Dataset,通常包含如下所示的 M 表达式。 遗憾的是,Tabular Editor 没有任何机制来“解析”这类表达式。不过,如果我们想在不知道原始值的情况下,把这个表达式中的服务器和数据库名称替换成别的内容,可以利用这样一个事实:这些值都被双引号括起来:
let
Source = Sql.Databases("devsql.database.windows.net"),
AdventureWorksDW2017 = Source{[Name="AdventureWorks"]}[Data],
dbo_DimProduct = AdventureWorksDW2017{[Schema="dbo",Item="DimProduct"]}[Data]
in
dbo_DimProduct
以下脚本会将双引号中第一次出现的值替换为服务器名称,并将双引号中第二次出现的值替换为数据库名称。 这两个替换值都从环境变量中读取:
// 这个脚本用于将所有 Power Query 分区中的服务器和数据库名称,
// 统一替换为通过环境变量提供的值:
var server = "\"" + Environment.GetEnvironmentVariable("SQLServerName") + "\"";
var database = "\"" + Environment.GetEnvironmentVariable("SQLDatabaseName") + "\"";
// 这个函数会从 M 表达式中提取所有被引号括起来的值,并以字符串列表形式返回
// (按出现顺序)。但如果某个引号前面紧跟井号(#),则忽略该引号中的值:
var split = new Func<string, List<string>>(m => {
var result = new List<string>();
var i = 0;
foreach(var s in m.Split('"')) {
if(s.EndsWith("#") && i % 2 == 0) i = -2;
if(i >= 0 && i % 2 == 1) result.Add(s);
i++;
}
return result;
});
var GetServer = new Func<string, string>(m => split(m)[0]); // 服务器名通常是遇到的第 1 个字符串
var GetDatabase = new Func<string, string>(m => split(m)[1]); // 数据库名通常是遇到的第 2 个字符串
// 遍历模型中的所有分区,把分区中的服务器和数据库名称替换为
// 环境变量中指定的值:
foreach(var p in Model.AllPartitions.OfType<MPartition>())
{
if (p.Expression.Contains("Source = Sql.Database"))
{
var oldServer = "\"" + GetServer(p.Expression) + "\"";
var oldDatabase = "\"" + GetDatabase(p.Expression) + "\"";
p.Expression = p.Expression.Replace(oldServer, server).Replace(oldDatabase, database);
}
}
用 Legacy 替换 Power Query 数据源和分区
如果你正在处理一个基于 Power BI 的模型,且该模型的分区使用 Power Query(M)表达式来访问基于 SQL Server 的数据源,那么很遗憾,你将无法使用 Tabular Editor 2 的“数据导入”向导,也无法执行架构检查(即比较已导入的列与数据源中的列)。
要解决这个问题,你可以在模型上运行下面的脚本:它会将 Power Query 分区替换为对应的原生 SQL 查询分区,并在模型中创建一个 Legacy(提供程序)数据源,这样就能使用 Tabular Editor 2 的“数据导入”向导:
这个脚本有两个版本:第一个版本会为创建的 Legacy 数据源使用 MSOLEDBSQL 提供程序,并使用硬编码的凭据。 这对本地开发很有用。 第二个脚本使用 SQLNCLI 提供程序。该提供程序在 Azure DevOps 的 Microsoft 托管构建代理上可用,并会从环境变量中读取凭据以及服务器/数据库名称,因此该脚本适合集成到 Azure Pipelines 中。
MSOLEDBSQL 版本:从 M 分区读取连接信息,并通过 Azure AD 提示你输入用户名和密码:
#r "Microsoft.VisualBasic"
// 这个脚本会将模型中的所有 Power Query 分区替换为一个
// 使用提供的连接字符串并采用 INTERACTIVE
// AAD 身份验证的 Legacy 分区。脚本假定所有 Power Query 分区
// 都从同一个基于 SQL Server 的数据源加载数据。
// 填入下面的信息:
var authMode = "ActiveDirectoryInteractive";
var userId = Microsoft.VisualBasic.Interaction.InputBox("输入你的 AAD 用户名", "用户名", "name@domain.com", 0, 0);
if(userId == "") return;
var password = ""; // 使用 ActiveDirectoryInteractive 身份验证时留空
// 这个函数会从 M 表达式中提取所有被引号括起来的值,并以字符串列表形式返回
// (按出现顺序)。但如果某个引号前面紧跟井号(#),则忽略该引号中的值:
var split = new Func<string, List<string>>(m => {
var result = new List<string>();
var i = 0;
foreach(var s in m.Split('"')) {
if(s.EndsWith("#") && i % 2 == 0) i = -2;
if(i >= 0 && i % 2 == 1) result.Add(s);
i++;
}
return result;
});
var GetServer = new Func<string, string>(m => split(m)[0]); // 服务器名通常是遇到的第 1 个字符串
var GetDatabase = new Func<string, string>(m => split(m)[1]); // 数据库名通常是遇到的第 2 个字符串
var GetSchema = new Func<string, string>(m => split(m)[2]); // 架构名通常是遇到的第 3 个字符串
var GetTable = new Func<string, string>(m => split(m)[3]); // 表名通常是遇到的第 4 个字符串
var server = GetServer(Model.AllPartitions.OfType<MPartition>().First().Expression);
var database = GetDatabase(Model.AllPartitions.OfType<MPartition>().First().Expression);
// 向模型添加一个 Legacy 数据源:
var ds = Model.AddDataSource("AzureSQL");
ds.Provider = "System.Data.OleDb";
ds.ConnectionString = string.Format(
"Provider=MSOLEDBSQL;Data Source={0};Initial Catalog={1};Authentication={2};User ID={3};Password={4}",
server,
database,
authMode,
userId,
password);
// 从所有表中移除 Power Query 分区,并将其替换为一个 Legacy 分区:
foreach(var t in Model.Tables.Where(t => t.Partitions.OfType<MPartition>().Any()))
{
var mPartitions = t.Partitions.OfType<MPartition>();
if(!mPartitions.Any()) continue;
var schema = GetSchema(mPartitions.First().Expression);
var table = GetTable(mPartitions.First().Expression);
t.AddPartition(t.Name, string.Format("SELECT * FROM [{0}].[{1}]", schema, table));
foreach(var p in mPartitions.ToList()) p.Delete();
}
SQLNCLI 版本:从环境变量中读取连接信息:
// 这个脚本会将模型中的所有 Power Query 分区替换为
// 一个 Legacy 分区,并从对应的环境变量中读取 SQL Server 名称、数据库名称、用户名
// 和密码。脚本假定所有 Power Query 分区都从同一个基于 SQL Server 的
// 数据源加载数据。
var server = Environment.GetEnvironmentVariable("SQLServerName");
var database = Environment.GetEnvironmentVariable("SQLDatabaseName");
var userId = Environment.GetEnvironmentVariable("SQLUserName");
var password = Environment.GetEnvironmentVariable("SQLUserPassword");
// 这个函数会从 M 表达式中提取所有被引号括起来的值,并以字符串列表形式返回
// (按出现顺序)。但如果某个引号前面紧跟井号(#),则忽略该引号中的值:
var split = new Func<string, List<string>>(m => {
var result = new List<string>();
var i = 0;
foreach(var s in m.Split('"')) {
if(s.EndsWith("#") && i % 2 == 0) i = -2;
if(i >= 0 && i % 2 == 1) result.Add(s);
i++;
}
return result;
});
var GetServer = new Func<string, string>(m => split(m)[0]); // 服务器名通常是遇到的第 1 个字符串
var GetDatabase = new Func<string, string>(m => split(m)[1]); // 数据库名通常是遇到的第 2 个字符串
var GetSchema = new Func<string, string>(m => split(m)[2]); // 架构名通常是遇到的第 3 个字符串
var GetTable = new Func<string, string>(m => split(m)[3]); // 表名通常是遇到的第 4 个字符串
// 向模型添加一个 Legacy 数据源:
var ds = Model.AddDataSource("AzureSQL");
ds.Provider = "System.Data.SqlClient";
ds.ConnectionString = string.Format(
"Server={0};Initial Catalog={1};Persist Security Info=False;User ID={2};Password={3}",
server,
database,
userId,
password);
// 从所有表中移除 Power Query 分区,并将其替换为一个 Legacy 分区:
foreach(var t in Model.Tables.Where(t => t.Partitions.OfType<MPartition>().Any()))
{
var mPartitions = t.Partitions.OfType<MPartition>();
if(!mPartitions.Any()) continue;
var schema = GetSchema(mPartitions.First().Expression);
var table = GetTable(mPartitions.First().Expression);
t.AddPartition(t.Name, string.Format("SELECT * FROM [{0}].[{1}]", schema, table));
foreach(var p in mPartitions.ToList()) p.Delete();
}